Magnum docs were missing the search functionality for some time because I wanted to implement it properly for the new theme. The proper implementation is now ready.
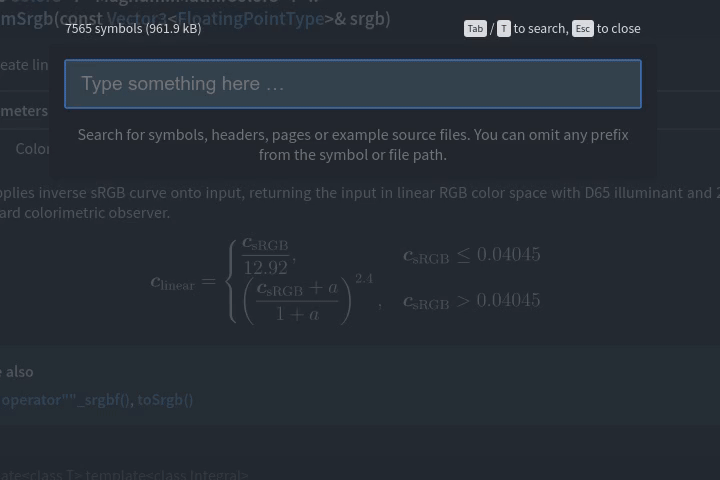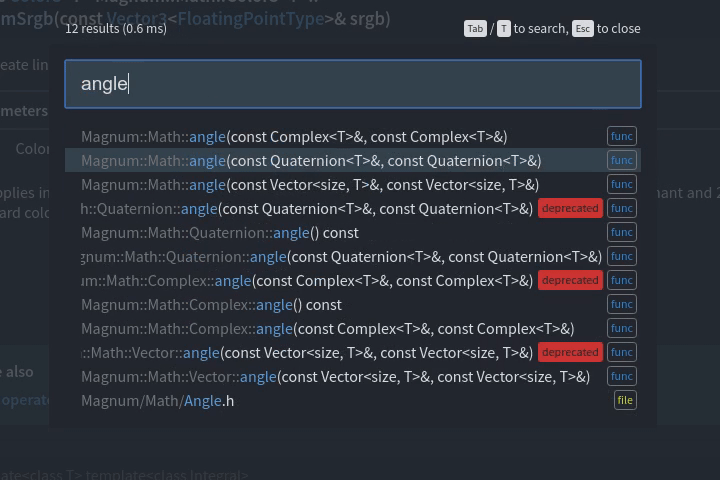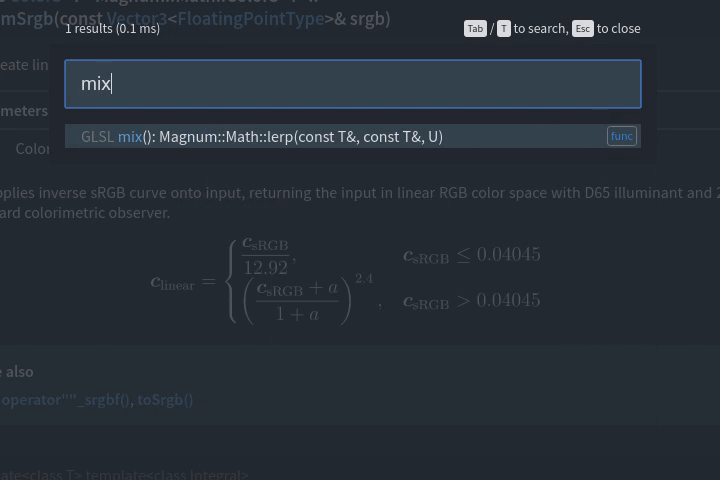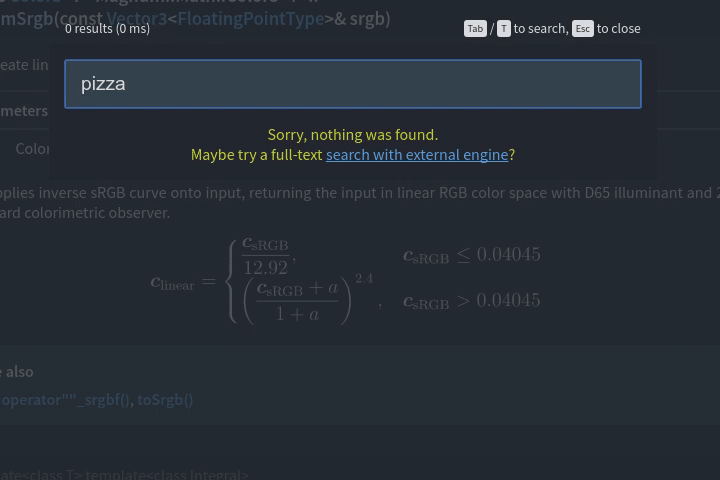
“How hard can it be?”
That’s what I told to myself about two weeks ago. I was so unhappy with the responsiveness and usability of the stock Doxygen search that I usually went straight to Google instead. With that experience, for the new theme I wanted a solution that:
- Is fast and stable, without results being reordered as they appear
- Is small enough to not need any complex server-side solution
- Is showing relevant results first, so I don’t need to scroll through endless lists to find what I’m looking for
- Is usable for API discovery (immediate lookahead autocompletion instead of being only a full-text search)
- Has an UX that allows me to pop it up anywhere on a page, navigate using just the keyboard and return back to the page without losing context
With not even 500 lines of pure JavaScript and roughly half a megabyte binary containing search data I’m able to search among all 7500 symbols of the Magnum engine faster than I can type.
The idea
The Trie search structure seemed to fit the case for lookahead autocompletion, however building a huge tree structure in JavaScript didn’t really get my hopes for better performance up. First hit when searching for “javascript fast tries” was this blog post by John Resig (the author of jQuery). I was quite horrified that even the fast implementation still involved building a tree structure until I saw that the article was written in 2011 — in the age before asm.js, typed arrays and Emscripten.
Phew, okay. I decided to drop “javascript” from my search query and a paper about Tightly packed tries finally popped up in the results. This started to look like the right direction to follow.
Initial implementation
The basic idea is: during output generation in the m.css Doxygen theme,
take the input search data and preprocess them to a trie structure using simple
nested Python dicts. Then, once fully populated, linearize the trie to
a binary file. The binary file will later be loaded using JavaScript in the
browser and search performed directly on it without building any new structure
out of it to minimize initial startup time and memory usage.
Each node in the trie will store a list of results (represented by simple integer indices to an external array, explanation below) and a map from characters to child nodes. I set a reasonable limit of 64k symbols in total, max binary file size to 256 MB, max 256 results and at most 256 child 8-bit characters for each node. With that, the binary serialization format for the trie is roughly as follows:
| Field size | Content |
|---|---|
| Root node offset | |
| … | … |
| Node N result count | |
| Node N child count | |
| Node N result indices | |
| Node N child 1 character + byte offset | |
| Node N child 2 character + byte offset | |
| … | … |
| Node N child character + byte offset | |
| … | … |
The trie will be traversed in post-order when serializing, which means that each node offset in the file is already known when serializing its parent. The only exception is the root node offset, which is updated at the start of the file as the last step.
Now, what actually will be saved into the trie? Let’s start with a very
simplified case: having the Magnum and Magnum::Math namespaces,
Magnum::Math::Vector and Magnum::Math::Range classes and just
three functions Magnum::Math::Vector::min(),
Magnum::Math::Range::min() and Magnum::Math::min(). The stock
Doxygen search allows me to only search using the leaf name — if I want to
look up Math::min(), entering min() gives too many results and I
need to filter the results manually, which is a waste of brain matter. The goal
here is to be able to search using any prefix, which means that each symbol
has to be saved into the trie with all its possible prefixes.
Having good debug visualization is key to understanding the data. A tuple containing the above seven symbols inserted with different prefixes looks like this — each column is one tree depth level (going to the next column involves searching for the correct letter) and particular leaf nodes contain result IDs (shown in cyan). The search is case-insensitive, so all strings are normalized to lowercase:
magnum [0] ||| ::math [1] ||| ::vector [2] ||| | ::min [3] ||| range [4] ||| | ::min [5] ||| min [6] ||th [1] ||| ::vector [2] ||| | ::min [3] ||| range [4] ||| | ::min [5] ||| min() [6] |in [3, 5, 6] vector [2] | ::min() [3] range [4] | ::min() [5]
Subtree merging
There’s one problem with the above approach — almost all symbols are contained in the trie two or more times, depending on their depth. With thousands of symbols this would be a significant size increase. Thanks to the debug visualization, the solution was immediately visible — what if I would simply eliminate subtrees that look the same?
During serialization the tree is traversed in post-order, which means that the final binary form of a node is known when serializing its parent. Then it’s enough to maintain a lookup table of serialized subtrees. When a new serialized subtree is already in the lookup table, it’s not written to the file but the byte offset of the already existing instance is used instead. This of course requires that subtrees with the same data are serialized the same, independent on their position in the file — in order to achieve that, I had to switch from relative child offsets (as suggested in the paper for space saving) to absolute offsets.
Comparing with the visualization above, # denotes where a
duplicate subtree was eliminated by this method:
magnum [0] ||| ::math [1] ||| ::vector [2] ||| | ::min [3] ||| range [4] ||| | ::min [5] ||| min [6] ||t# |in [3, 5, 6] v# r#
With the subtree merging in place, the serialized size of this minimal case went down from 592 bytes to not even a half: 290 bytes. In the full Magnum search data, this saved over half a megabyte. A nice thing about this approach is that it’s completely language-oblivious — it just works on the binary data.
Result map
So far there was just the trie that contained result indices such as
[3, 5, 6]. That’s
obviously not enough to show a link with search result to the user. Next to the
trie there has to be a map from those indices to actual result titles and URLs.
Each title and URL is a string of a different length and in order to make the lookup a constant-time operation, there needs to be first a table mapping an index to byte offset with the string data. Because in the trie data I’m using only 24 bits for byte offset, I can do the same here and use the remaining 8 bits for various additional information, such as symbol type.
| Field size | Content |
|---|---|
| Result 0 flags + byte offset | |
| Result 1 flags + byte offset | |
| … | … |
| Result N flags + byte offset | |
| File size | |
Result 0 title, '\0', URL |
|
| … | … |
Result N title, '\0', URL |
Looking up a result involves reading data from byte offset range given by index and . The title and URL is null-separated. Result data corresponding to the above simplified case look like this when visualized:
0: Magnum [type=NAMESPACE] -> namespaceMagnum.html 1: Magnum::Math [type=NAMESPACE] -> namespaceMagnum_1_1Math.html 2: Magnum::Math::Vector [type=CLASS] -> classMagnum_1_1Math_1_1Vector.html 3: Magnum::Math::Vector::min() [type=FUNC] -> classMagnum_1_1Math_1_1Vector.html#af029f9f7810201f0bd8d9580af273bde 4: Magnum::Math::Range [type=CLASS] -> classMagnum_1_1Math_1_1Range.html 5: Magnum::Math::Range::min() [type=FUNC] -> classMagnum_1_1Math_1_1Range.html#ad4919361a2086212fac96da0221e4dcd 6: Magnum::Math::min() [type=FUNC] -> namespaceMagnum_1_1Math.html#ae22ef0cb2a5a5e4c5e626a3df670be21
Result map prefix merging
Again, thanks to the data visualization it’s immediately clear that there’s a
lot of redundant information that’s negatively affecting data size. The
redundant information is mainly in prefixes, so I reused the already
implemented trie to perform the optimization. The following visualization shows
the result — the details are way too boring to explain in full here, but
basically every entry title can be optionally prefixed by another entry title
(denoted by prefix=M) and take the first [:N]
characters from that entry URL, recursively.
0: Magnum [type=NAMESPACE] -> namespaceMagnum.html 1: ::Math [prefix=0[:15], type=NAMESPACE] -> _1_1Math.html 2: ::Vector [prefix=1[:0], type=CLASS] -> classMagnum_1_1Math_1_1Vector.html 3: ::min() [prefix=2[:34], type=FUNC] -> #af029f9f7810201f0bd8d9580af273bde 4: ::Range [prefix=1[:0], type=CLASS] -> classMagnum_1_1Math_1_1Range.html 5: ::min() [prefix=4[:33], type=FUNC] -> #ad4919361a2086212fac96da0221e4dcd 6: ::min() [prefix=1[:28], type=FUNC] -> #ae22ef0cb2a5a5e4c5e626a3df670be21
In this particular case the map size went down from 494 bytes to 321 bytes. In case of Magnum data, the saving was over a megabyte.
Client-side search
With the binary data in hands I was finally ready to leave the Python world and start the client-side JavaScript implementation. Motivated by how Emscripten is able to run huge codebases with minimal garbage collector involvement, I reached directly to typed arrays and implemented the whole search directly on the binary data.
Boring details aside, the client-side search functionality works simply by following the pointer to the root trie node and then consuming the search string one 8-bit character at a time. The child lookup is performed using a simple linear search (contrary to what the paper suggests), as that is fast enough and not the bottleneck. The child count has some reasonable upper bound (which is not even 256, more like 26 or so), so the big-O notation for this lookup is , linear with search string size. Fast.
However, with just a lookup the search would show the results only if the user
entered the whole search string (for example min()). That would be
wasting users’ time and not really improving API discoverability.
The lookahead autocompletion is performing a breadth-first tree search,
collecting result indices along the way, shortest results first. With the above
trie, searching for just m, the autocompletion would collect the following
output:
[{title: 'Magnum::Math::min()', // matching the `min` suffix url: 'namespaceMagnum_1_1Math.html#ae22ef0cb2a5a5e4c5e626a3df670be21' }, {title: 'Magnum::Math::Range::min()' // matching the `min` suffix url: 'classMagnum_1_1Math_1_1Range.html#a22af2191e4ab88b45f082ef14aa45185'}, {title: 'Magnum::Math::Vector::min()' // matching the `min` suffix url: 'classMagnum_1_1Math_1_1Vector.html#af029f9f7810201f0bd8d9580af273bde'}, {title: 'Magnum::Math', // matching the `Math` suffix url: 'namespaceMagnum_1_1Math.html'}, {title: 'Magnum', // matching the `Magnum` suffix url: 'namespaceMagnum.html'}, {title: 'Magnum::Math::min()' // matching the `Math::min` suffix url: 'classMagnum_1_1Math_1_1Vector.html#af029f9f7810201f0bd8d9580af273bde'}, {title: 'Magnum::Math::Range', // matching the `Math::Range` suffix url: 'classMagnum_1_1Math_1_1Range.html'}, ...
Unlike looking up the search string, this is the bottleneck — and as just
about everything in Magnum starts with m (and not just C++ symbols, don’t
forget about preprocessor macros, directories and files), such autocompletion
can spew out endless pages of results on entering the first character.
Lookahead barriers
Looking at the above, something seems off. It’s definitely not the user’s expectation to get to know about all symbols that ever existed when entering a bunch of characters. For example, when I’m searching for a namespace, I am not interested in all its members. Or when a some prefix is appearing both in function name and enclosing namespace, I’ll get the result twice in the list.
So how to solve that? When adding symbols to the trie, let’s add barriers to
signal the lookahead autocompletion that it should not dig deeper looking for
possible results. However, I don’t want to prevent API discovery, so when one
enters e.g. Magnum:, the search should go past the barrier and show all
members of the namespace. (But not nested members!)
In the following visualization, the $ characters denote a
lookahead barrier. If the autocompletion reaches a symbol that’s in front of
it, it will not attempt to continue further.
magnum [0] ||| :$ ||| :math [1] ||| :$ ||| :vector [2] ||| | :$ ||| | :min [3] ||| range [4] ||| | :$ ||| | :min [5] ||| min [6] ||th [1] ||| :$ ||| :vector [2] ||| | :$ ||| | :min [3] ||| range [4] ||| | :$ ||| | :min [5] ||| min [6] |in [3, 5, 6] vector [2] | :$ | :min [3] range [4] | :$ | :min [5]
With these barriers in place, searching for m gives the following output
— unique symbols starting with m, sorted from shortest to longest:
[{title: 'Magnum::Math::min()', url: 'namespaceMagnum_1_1Math.html#ae22ef0cb2a5a5e4c5e626a3df670be21'}, {title: 'Magnum::Math::Range::min()', url: 'classMagnum_1_1Math_1_1Range.html#a22af2191e4ab88b45f082ef14aa45185'}, {title: 'Magnum::Math::Vector::min()', url: 'classMagnum_1_1Math_1_1Vector.html#af029f9f7810201f0bd8d9580af273bde'}, {title: 'Magnum::Math', url: 'namespaceMagnum_1_1Math.html'}, {title: 'Magnum', url: 'namespaceMagnum.html'}]
Searching for math gives just this:
[{title: 'Magnum::Math', url: 'namespaceMagnum_1_1Math.html'}]
While searching for math: provides a list of all its immediate members:
[{title: 'Magnum::Math::min()', url: 'namespaceMagnum_1_1Math.html#ae22ef0cb2a5a5e4c5e626a3df670be21'}, {title: 'Magnum::Math::Range', url: 'classMagnum_1_1Math_1_1Range.html'}, {title: 'Magnum::Math::Vector', url: 'classMagnum_1_1Math_1_1Vector.html'}]
Extra goodies
Just replicating the stock search functionality and making it faster would be
boring, so I added some cherries on top. First is propagating info about
deprecated and deleted functions to search results (and member listing
as well) to save some the users extra clicks when trying to find a function
that’s actually callable. You can see it in the GIF above.
The second feature is ability to specify additional search keywords for
particular symbols. This is useful especially in the OpenGL wrapping layer of
Magnum — one can search for a well-known OpenGL symbol to get to know what
API it corresponds to. This is exposed through custom @m_keywords,
@m_keyword and @m_enum_values_as_keywords commands, head over
to the docs for
details. Self-explanatory example:
/** * @brief Set texture storage * * @m_keywords{glTexStorage2D() glTextureStorage2D()} */ Texture2D& Texture2D::setStorage(...); /** * @brief Renderer feature * * @m_enum_values_as_keywords */ enum class RendererFeature: GLenum { /** Depth test */ DepthTest = GL_DEPTH_TEST, ... };
Final implementation
In this article I tried to explain mainly the key aspects of the search implementation . The rest is important too, but would make the article too long and boring.
- In order to properly highlight the currently typed part of the search
result, the trie lookup is counting number of suffix characters when
gathering the results. This is extended further in order to display
function arguments lists and
const/ r-value overloads (which are not part of the trie data). - Due to restrictions of Chromium-based browsers,
it’s not possible to download data using
XMLHttpRequestwhen served from a local file-system. Because that’s a very common use case, I had to work around this by converting the binary to a Base85-encoded *.js file that’s loaded directly via<script>. - A lot of effor went into client-side UX, like keyboard navigation, cutting off overly long prefixes on the proper side, avoiding page jumps etc. There are still some known issues left to be resolved.
Some stats
With the current state of Magnum documentation, where there is 7565 unique
symbols and I’m in the middle of adding @m_keywords to all OpenGL wrapper
APIs, the data size is as follows, depending on what features are enabled:
| Data type | Uncompressed | Gzipped |
|---|---|---|
| Baseline, binary | 2635.6 kB | 884.2 kB |
| Subtree merging, binary | 2033.3 kB | 537.8 kB |
| Subtree and prefix merging, binary | 959.3 kB | 501.5 kB |
| Subtree and prefix merging, base85 | 1202.5 kB | 752.5 kB |
As the docs are accessed through a webserver, I can use the binary and enable server-side gzip compression. That gives slightly below half a megabyte, which, in comparison to sizes of contemporary websites, is more than okay. The documentation is updated not more than once a week, so the browsers will usually just happily serve this dataset from a cache.
One important thing to note: the prefix merging doesn’t give really that much advantage when comparing the gzipped size, as the data are already very nicely compressible.
Bonus: Unicode
Someone might say that the above restriction to 8-bit characters makes this not Unicode-aware and thus useless beyond simple ASCII symbols. Well, no. Assuming the input is UTF-8-encoded, this is how a trie for two great Czech words “hýždě” and “hárá” will look like:
h0xc3 0xbd 0xc5 | 0xbe | d0xc4 | 0x9b | [13] 0xa1 r0xc3 | 0xa1 | [42]
The implementation simply takes the UTF-8 representation of the word
“hýždě” ['h', 0xc3, 0xbd, 0xc5, 0xbe, 'd', 0xc4, 0x9b]
byte-by-byte and inserts that into the trie, not giving much thought to
whatever encoding given string is in. This also has the effect that UTF-8
representation of “ý” and “á” is
[0xc3, 0xbd] and [0xc3, 0xa1] respectively, sharing the same first
byte 0xc3, which is then a single node in the trie. That means there’s no
need to have more that 8 bits to represent a character in the trie.
Try it yourself
Oh, did I mention that this whole thing is fully open-source and ready for you to try it out? Head over to the full documentation of the m.css Doxygen theme for details. Bug reports very welcome, and if you like what you see, consider making a donation. Thank you!