Being productive with your tools
Magnum is developed with a “Zen Garden” philosophy in mind, focusing on productivity, predictability and ease of use. Let’s see how that can extend beyond just the library itself — into your daily workflow.
Triggered by an (admittedly very harsh) recent article by @cliffski, a recent need to reboot into Windows 10 in order to fix MSVC 2019 support in Magnum (to be horrified from the UX of Windows 10), and a resulting discussion on our Gitter chat, I decided to share what I think is useful for being a productive developer. In this case with Linux and the KDE Plasma 5 desktop being my system of choice.
Git is a friend, not a despised enemy
Think of Git not as of the annoying obscure last-mile tool to “push your code to customers”, but a tool that can actively keep you focused, organized, help you review your changes, have your edit history safe and let you easily pick up interrupted work from yesterday.
I’m regularly using git status and git diff as a “scope guard” — to
avoid the set of changes in my working copy growing too large. Then I’m using
the interactive git add -i
to pick relevant changes and commit them into as many separate commits as
desirable, often using git rebase -i
to back-integrate fixup patches to existing commits.
There’s nothing easier than doing a quick git stash to see if your latest
modifications are to blame for broken tests or if it’s something else.
Some people argue that “[their] job is coding, not making beautiful commit logs”,
but from my experience scoping up a task into a sequence of clean commits helps
a lot — if the diff is self-contained, makes sense and doesn’t contain
unrelated changes, you can review your work much easier and be sure you
didn’t mess anything up. It pays off later when investigating bugs as well,
git blame together with git bisect are powerful tools for pinning down
issues in large or unfamiliar codebases. But they need a clean history to work
properly.
Get to know your editor, shell and keyboard layout
While every editor is different, there are a few features I absolutely demand to consider it usable. If the editor starts slow, has a typing lag, can’t apply a consistent indentation and whitespace policy, doesn’t know block editing or commenting/uncommenting code isn’t a key shortcut, then it’s useless for me. Kate from KDE (and everything based on it — KWrite, KDevelop) is my editor of choice. I have to admit I never bothered to learn Vim — mostly because the current way I edit files is fast enough, the bottleneck being my brain and not “how fast I can type”.
Knowing how to navigate with keyboard is essential as well — far too often I see senior programmers with 20+ years of experience moving across words or lines only by repeatedly pressing arrow keys like if there was no other way. Ctrl Arrow skips whole words and there’s Home / End, use them! On Mac, however, I was never able to have those work consistently across apps and it’s one of reasons why I’d rather SSH into a Mac than use its keyboard directly.
Pick a shell where you can work fast — 90% of what you do there is repeatedly
executing short commands, so it’s essential to have this optimized. The plain
Windows cmd.exe is absolutely terrible at that, but most other shells can
be made a joy to work with if you configure their history handling. If you are
on Windows and can’t or don’t want to use Git Bash (which contains readline
and thus can be made usable), have a look at Clink.
"\e[A":history-search-backward "\e[B":history-search-forward
Paste this into your /etc/inputrc, open a new terminal, type a command
prefix and pres Up to autocomplete it from typed history.
Simple and intuitive. You can thank me later.
Have your desktop work for you
I have a single external 27” 4K screen. It practically covers my field of view and fits everything I can focus on in a single moment, but not more. By choice — I currently don’t have any desire to use more than one screen. What I usually see elsewhere is people having one screen with an IDE and the other with a single Slack window, an e-mail or a browser, with all the messages, animated ads and notifications constantly begging for attention, only making focused work miserable.
What I have instead is six virtual desktops — one dedicated for the browser, another three for work, one desktop solely for file / package management and one with a music player. This makes it possible to have each virtual desktop a single area of focus, compared to a pile of windows the IDE won’t distract you when reading a PDF and a browser window won’t distract from coding. It’s important that the taskbar shows only windows from the current desktop and nothing else. Recently I even turned off all browser push notifications so activity from one virtual desktop doesn’t leak into others in any way.

Important for desktop switching shortcuts is that they’re absolute (so I don’t have to think about direction, just the destination) and that there’s no animation — if the brain is focused on a particular screen area, quick switching to another desktop and back will not cause it to lose context. That’s also why I never use Alt Tab, it has an unpredictable order and causes so much visual noise that losing context is inevitable. Another essential feature is an ability to make a window stay always on top or be present on all virtual desktops — a floating console window with a long-running operation, for example.
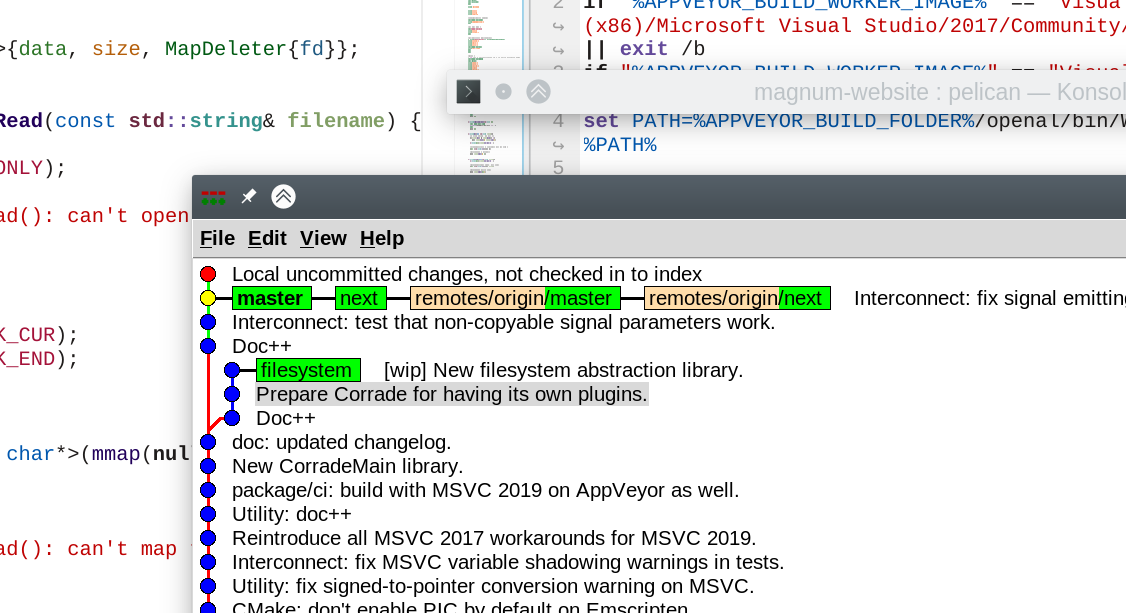
gitk stays on top while editing code in a fullscreen
IDE below; a “rolled-up” console window with a long-running operation above
it.Your computer can be a power-house
It’s common for me to have a browser with 100+ tabs open, two IDEs with ~50 files each, several console windows each with multiple tabs, file manager with five split tabs, a dozen of PDFs open on top and a spreadsheet for procrastinating on my taxes. When I finish my work, I put the laptop to sleep and when I resume work the next day, it’s all there, exactly how I left it. Uptime of 90 days isn’t anything extraordinary either.
A laptop with 16 GB of RAM, often running only at 800 MHz, has no problem keeping up with all that. But it’s important that I can rely on the system to not do any shady business in the background — hogging the CPU with an antivirus check or downloading gigabytes of system updates unless I tell it to (and then randomly rebooting) would be an absolute showstopper.
Little Big Things
On KDE Plasma, if I press Alt F2, KRunner, a popup search window, appears. It can open apps, search tabs in my browser, do simple calculations but also has a plugin that gives me access to a database of pre-defined symbols — whether I need an em-dash for a tweet, a trademark character or a ¯\_(ツ)_/¯ response for a chat. A critical requirement is that it has to work predictably and without any delay; typing a known prefix and pressing Enter will always give the same result, no matter how fast I type.
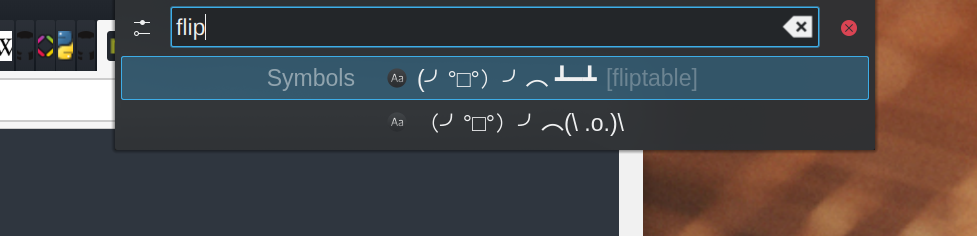
Another very handy thing is a global keyboard history. More often than not, you need to copy several things at once, not just one. Or you accidentally copy something and lose the precious clipboard contents. Especially when you need to switch windows or desktops to copy multiple things, the visual noise will make your brain go out of the zone very quickly. With Klipper I can use Ctrl Alt Up or Down to pick a different entry from the clipboard history.
Python is the best calculator, shell and knife
It’s a good idea to have a pen and a piece of paper on your desk, especially when you are coding visual things. Using it to calculate a dot product by hand isn’t. A terminal window with an interactive Python instance is a much better tool. And with Magnum now getting Python bindings, it has everything needed.
>>> from magnum import * >>> Matrix3.rotation(Deg(45)) Matrix(0.707107, -0.707107, 0, 0.707107, 0.707107, 0, 0, 0, 1)
Quick, where are the minus signs in a 2D rotation matrix?
Python is the go-to choice also for all string-processing shell scripts longer
than one line — instead of trying to remember how
to use awk and cut inside a while loop in Bash, whip that up in
Python. It’ll be easier to debug, extend and you wouldn’t need to learn the
obscure tools again a week later.
Fast iteration times are key
There’s no worse productivity killer than a tool that makes me wait until an operation is done. That’s a forced interruption and my brain immediately gives up on all context. I can iterate or core APIs in Magnum basically without interruption, incremental compilation taking few seconds at most. Then, with Utility::Tweakable, I can live-edit constants in a running app for even faster turnaround times.
In contrast, Magnum’s Python bindings are done with pybind11, which exposes a very simple API doing very complex things underneath. However I soon got into a state where the iteration time of a single compile & link got to almost a minute — the whole engine with 800 targets compiles from scratch faster than that. To stay occupied during this “downtime”, I temporarily switch to another task, but the context switch overhead slowly makes the focus disappear.
Have a stack you can trust …
With Magnum not far from being a decade old, I have the luxury of relying on a mature, stable and well-tested codebase. Developing new things on top of a trusted stack is a breeze, because combining well-tested and well-understood building blocks most often leads to the result behaving correctly as well — with any debugging happening only on the surface level.
This extends to providing support as well — knowing the internals well I can quickly narrow down a reported problem, remotely diagnose it by asking just a few questions and provide either a solution or a workaround almost immediately.
… and several alternatives for the stacks you can’t
Not everything is a “Zen Garden”, though — there’s the OS, GPU drivers, third party libraries, compilers and hardware, each at a various state of stability. For those it’s important to always have an alternative implementation to test on — if an image fails to load with one plugin, try with another. If a shader works flawlessly on one GPU, it might as well crash and burn on another.
Try to primarily develop against the most conforming implementation (of a compiler, standard library, GPU driver, file format loader) and regularly test on at least one other, to verify your assumptions. Investing a week (or even a month) of your time into setting up a CI test matrix that does automatic testing for you on several different platforms, ideally including GPU code, will pay back multiple times.

Web is unfortunately just too damn slow
Ever since I made the lightweight Magnum website and docs, the rest of the Internet comparatively started to feel much slower. While I can jump to a documentation of MeshTools::generateSmoothNormals() in a fraction of a second, navigating to a particular issue of a particular project through the GitHub UI to write a reply is so slow that it’s faster for me to just recall its number and type the whole address out.
For external libraries I’m using, I often end up regenerating the docs myself
using m.css. The search functionality
of any Sphinx-generated docs is a bad joke and Googling the actual
behavior of Python’s splitlines() isn’t nearly as straightforward as it
should be either. I ended up building my own searchable copy of
Eigen documentation, did a similar thing
for Android NDK and
I’m planning to do that for Python standard library as well.
Worth mentioning is Zeal, providing offline docs for various libraries. I never used it myself, so can’t comment further.