Flexible and efficient mesh representation, custom attributes, new data types and a ton of new processing, visualization and analyzing tools. GPU-friendly geometry storage as it should be in the 21st century.
During the past six months, Magnum had undergone a rather massive rework of its
very central parts — mesh data import and storage. The original (and now
deprecated) Trade::MeshData2D / Trade::MeshData3D classes stayed
basically intact from the early 2010s when Magnum was nothing more than a toy
project of one bored university student, and were overdue for a replacement.
How to not do things
While the GL::Mesh and GL::Attribute on the renderer side provided all imaginable options for data layout and vertex formats, the flexibility bottleneck was on the importer side. Increasingly unhappy about the limitations, I ended up suggesting people to just sidestep the Trade APIs and make their own representation when they needed to do anything non-trivial. However, working on the replacement, I discovered — the horror — that Magnum was far from the only library with such limitations embedded in its design.
explicit MeshData3D(MeshPrimitive primitive, std::vector<UnsignedInt> indices, std::vector<std::vector<Vector3>> positions, std::vector<std::vector<Vector3>> normals, std::vector<std::vector<Vector2>> textureCoords2D, std::vector<std::vector<Color4>> colors, const void* importerState = nullptr);
Source: Magnum/Trade/MeshData3D.h deprecated
Here is the original Magnum API. While it allowed multiple sets of all
attributes (usable in mesh morphing, for example), adding a new attribute type
meant adding another vector-of-vectors (and updating calls to this constructor
everywhere), not to mention lack of support any sort of custom attributes or
ability to store different data types. The importerState is an extension
point that allows accessing arbitrary additional data, but it’s
plugin-dependent and thus not usable in a generic way.
struct aiMesh { aiVector3D* mVertices; aiVector3D* mNormals; aiVector3D* mTangents; aiVector3D* mBitangents; aiColor4D* mColors[…]; aiVector3D* mTextureCoords[…]; aiFace* mFaces; … };
Source: assimp/mesh.h
Perhaps the most widely used asset import library, Assimp, has it very similar. All attributes are tightly packed and in a fixed type, and while it supports a few more attribute types compared to the original Magnum API, it has no custom attributes or formats either.
Fixed index and attribute types mean that input data has to be de-interleaved and expanded to 32-bit ints and floats in order to be stored here, only to have them interleaved and packed again later to have efficient representation on the GPU. Both of those representations also own the data, meaning you can’t use them to reference external memory (for example a memory-mapped file or a GPU buffer).
The ultimate winner of this contest, however, is libIGL, with the following function signature. Granted, it’s templated to allow you to choose a different index and scalar type, but you have to choose the type upfront and not based on what the file actually contains, which kinda defeats the purpose. What’s the most amazing though is that every position and normal is a three-component std::vector, every texture coordinate a two-component vector and then each face is represented by another three vector instances. So if you load a 5M-vertex mesh with 10M faces (which is not that uncommon if you deal with real data), it’ll be spread across 45 millions of allocations. Even with keeping all the flexibility It could be just a handful1, but why keep your feet on the ground, right? The std::string passed by value is just a nice touch on top.
template <typename Scalar, typename Index> IGL_INLINE bool readOBJ( const std::string obj_file_name, std::vector<std::vector<Scalar > > & V, std::vector<std::vector<Scalar > > & TC, std::vector<std::vector<Scalar > > & N, std::vector<std::vector<Index > > & F, std::vector<std::vector<Index > > & FTC, std::vector<std::vector<Index > > & FN, std::vector<std::tuple<std::string, Index, Index >> &FM );
Source: igl/readOBJ.h
- 1.
- ^ To be fair, libIGL has an overload that puts the result into just six regularly-shaped Eigen matrices. However, it’s implemented on top of the above (so you still need a military-grade allocator) and it requires you to know beforehand that all faces in the file have the same size.
Can we do better?
The original pipeline (and many importer libraries as well) got designed with an assumption that a file has to be parsed in order to get the geometry data out of it. It was a sensible decision for classic textual formats such as OBJ, COLLADA or OpenGEX, and there was little point in parsing those to anything else than 32-bit floats and integers. For such formats, a relatively massive amount of processing was needed either way, so a bunch of more copies and data packing at the end didn’t really matter:

The new pipeline turns this assumption upside down, and instead builds on a simple design goal — being able to understand anything that the GPU can understand as well. Interleaved data or not, half-floats, packed formats, arbitrary padding and alignment, custom application-specific attributes and so on. Then, assuming a file already has the data exactly as we want it, it can simply copy the binary blob over to the GPU and only parse the metadata describing offsets, strides and formats:

For the textual formats (and rigidly-designed 3rd party importer libraries) it means the importer plugin now has to do extra work that involves packing the data into a single buffer. But that’s an optimization done on the right side — with increasing model complexity it will make less and less sense to store the data in a textual format.
Enter the new MeshData
The new Trade::MeshData class accepts just two memory buffers — a typeless index buffer and a typeless vertex buffer. The rest is supplied as a metadata, with Containers::StridedArrayView powering the data access (be sure to check out the original article on strided views). This, along with an ability to supply any MeshIndexType and VertexFormat gives you almost unlimited2 freedom of expression. As an example, let’s say you have your positions as half-floats, normals packed in bytes and a custom per-vertex material ID attribute for deferred rendering, complete with padding to ensure vertices are aligned to four-byte addresses:
struct Vertex { Vector3h position; Vector2b normal; UnsignedShort:16; UnsignedShort objectId; }; Containers::Array<char> indexData; Containers::Array<char> vertexData; Trade::MeshIndexData indices{MeshIndexType::UnsignedShort, indexData}; Trade::MeshData meshData{MeshPrimitive::Triangles, std::move(indexData), indices, std::move(vertexData), { Trade::MeshAttributeData{Trade::MeshAttribute::Position, VertexFormat::Vector3h, offsetof(Vertex, position), vertexCount, sizeof(Vertex)}, Trade::MeshAttributeData{Trade::MeshAttribute::Normal, VertexFormat::Vector2bNormalized, offsetof(Vertex, normal), vertexCount, sizeof(Vertex)}, Trade::MeshAttributeData{Trade::MeshAttribute::ObjectId, VertexFormat::UnsignedShort, offsetof(Vertex, objectId), vertexCount, sizeof(Vertex)} } };
The resulting meshData variable is a self-contained instance containing all
vertex and index data of the mesh. You can then for example pass it directly to
MeshTools::compile() — which will upload the indexData and
vertexData as-is to the GPU without any processing, and configure it so the
builtin shaders can transparently interpret the half-floats and normalized
bytes as 32-bit floats:
GL::Mesh mesh = MeshTools::compile(meshData); Shaders::Phong{}.draw(mesh);
The data isn’t hidden from you either — using indices() or attribute() you can directly access the indices and particular attributes in a matching concrete type …
Containers::StridedArrayView1D<const UnsignedShort> objectIds = meshData.attribute<UnsignedShort>(Trade::MeshAttribute::ObjectId); for(UnsignedShort objectId: objectIds) { // … }
… and because there’s many possible types and not all of them are directly usable (such as the half-floats), there are indicesAsArray(), positions3DAsArray(), normalsAsArray() etc. convenience accessors that give you the attribute unpacked to a canonical type so it can be used easily in contexts that assume 32-bit floats. For example, calculating an AABB of whatever position type is just an oneliner:
Range3D aabb = Math::minmax(meshData.positions3DAsArray());
Among the evolutionary things, mesh attribute support got extended with tangents and bitangents (in both representations, either a four-component tangent that glTF uses or a separate three-component bitangent that Assimp uses), and @Squareys is working on adding support for vertex weights and joint IDs in mosra/magnum#441.
- 2.
- ^ You still need to obey the limitations given by the GPU, such as the index buffer being contiguous, all attributes having the same index buffer or all faces being triangles. Unless you go with meshlets.
Tools to help you around
Of course one doesn’t always have data already packed in an ideal way, and doing so by hand is tedious and error-prone. For that, the MeshTools library got extended with various utilities operating directly on Trade::MeshData. Here’s how you could use MeshTools::interleave() to create the above packed representation from a bunch of contiguous arrays, possibly together with Math::packInto(), Math::packHalfInto() and similar. Where possible, the actual VertexFormat is inferred from the passed view type:
Containers::ArrayView<const Vector3h> positions; Containers::ArrayView<const Vector2b> normals; Containers::ArrayView<const UnsignedShort> objectIds; Containers::ArrayView<const UnsignedShort> indices; Trade::MeshData meshData = MeshTools::interleave( Trade::MeshData{MeshPrimitive::Triangles, {}, indices, Trade::MeshIndexData{indices}, UnsignedInt(positions.size())}, {Trade::MeshAttributeData{Trade::MeshAttribute::Position, positions}, Trade::MeshAttributeData{Trade::MeshAttribute::Normal, normals}, Trade::MeshAttributeData{Trade::MeshAttribute::ObjectId, objectIds}} );
Thanks to the flexibility of Trade::MeshData, many of historically quite verbose operations are now available through single-argument APIs. Taking a mesh, interleaving its attributes, removing duplicates and finally packing the index buffer to the smallest type that can represent given range can be done by chaining MeshTools::interleave(), MeshTools::removeDuplicates() and MeshTools::compressIndices():
Trade::MeshData optimized = MeshTools::compressIndices( MeshTools::removeDuplicates( MeshTools::interleave(mesh)));
There’s also MeshTools::concatenate() for merging multiple meshes together, MeshTools::generateIndices() for converting strips, loops and fans to indexed lines and triangles, and others. Except for potential restrictions coming from given algorithm, each of those works on an arbitrary instance, be it an indexed mesh or not, with any kind of attributes.
Apart from the high-level APIs working on Trade::MeshData instances, the existing MeshTools algorithms that work directly on data arrays were ported from std::vector to Containers::StridedArrayView, meaning they can be used on a much broader range of inputs.
Binary file formats make the computer happy
With a mesh representation matching GPU capabilities 1:1, let’s look at a few examples of binary file formats that could make use of it, their flexibility and how they perform.
glTF

glTF — interleaved attributes or not, do what you want as long as indices stay contiguous
The “JPEG of 3D” and its very flexible
binary mesh data representation was actually the initial trigger for this work
— “what if we could simply memory-map the *.glb and render directly off
it?”. In my opinion the current version is a bit too limited in the choice of
vertex formats (no half-floats, no 10.10.10.2 or float 11.11.10
representations for normals and quaternions), but that’s largely due to its
goal of being fully compatible with unextended WebGL 1 and nothing an extension
couldn’t fix.
To make use of a broader range of new vertex formats, Magnum’s
TinyGltfImporter got extended to support the
KHR_mesh_quantization
glTF extension, together with
KHR_texture_transform,
which it depends on. Compared to the more involved compression schemes
quantization has the advantage of not requiring any decompression step, as the
GPU can still understand the data without a problem. A quantized mesh will have
its positions, normals and texture coordinates stored in the smallest possible
type that can still represent the original data within reasonable error bounds.
So for example texture coordinates in a range of will get
packed to a 8-bit range and offset + scale needed to
dequantize them back to original range is then provided through the texture
transformation matrix. The size gains vary from model to model and depend on
the ratio between texture and vertex data. To show some numbers, here’s a
difference with two models from the glTF-Sample-Models
repository, converted using the gltfpack utility from meshoptimizer
(more on that below):
- JSON data size
- image data size
- mesh data size
While packed attributes are supported by the GPU transparently, the builtin Shaders::Phong and Shaders::Flat had to be extended to support texture transform as well.
Stanford PLY

PLY — interleaved per-vertex position, normal and color data, followed by size and indices of each face
PLY is a very simple, yet surprisingly flexible and extensible format. Magnum has the StanfordImporter plugin for years, but following the Trade::MeshData redesign it gained quite a few new features, among which is support for vertex colors, normals, texture coordinates and object IDs. PLYs also support 8- and 16-bit types for vertex data, and similarly to glTF’s KHR_mesh_quantization support are now imported as-is, without expansion to floats.
Because PLYs are so simple and because PLYs are very often used for massive scanned datasets (Stanford Bunny being the most prominent of them), I took this as an opportunity to investigate how far can Magnum reduce the import time, given that it can have the whole chain under control. Plotted below is import time of a 613 MB scan model3 with float positions, 24-bit vertex colors and a per-face 32-bit object ID property that is purposedly ignored. Measured times start with the original state before the Trade::MeshData rework, compare AssimpImporter and StanfordImporter configured for fastest import4 and show the effect of additional optimizations:
- 4.
- ^ a b For AssimpImporter, the on-by-default
JoinIdenticalVertices,TriangulateandSortByPTypeprocessing options were turned off, as those increase the import time significantly for large meshes. To have a fair comparison, in case of StanfordImporter theperFaceToPerVertexoption that converts per-face attributes to per-vertex was turned off to match Assimp that ignores per-face attributes completely. - 5.
- ^ In case of StanfordImporter, the main speedup comes from all push_back()s replaced with a Utility::copy(), which is basically a fancier std::memcpy() that works on strided arrays as well. AssimpImporter instead assign()ed the whole range at once which is faster, however the absolute speedup was roughly the same for both. Unfortunately not enough for Assimp to become significantly faster. Commit mosra/magnum-plugins@79a185b and mosra/magnum-plugins@e67c217.
- 6.
- ^ a b The original StanfordImporter implementation was using std::getline() to parse the textual header and std::istream::read() to read the binary contents. Loading the whole file into a giant array first and then operating on that proved to be faster. Commit mosra/magnum-plugins@7d654f1.
- 7.
- ^ PLY allows faces to have arbitrary N-gons, which means an importer has to go through each face, check its vertex count and triangulate if needed. I realized I could detect all-triangle files based solely by comparing face count with file size and then again use Utility::copy() to copy the sparse triangle indices to a tightly packed resulting array. Commit mosra/magnum-plugins@885ba49.
- 8.
- ^ a b c To make plugin implementation easier, if a plugin doesn’t provide a dedicated doOpenFile(), the base implementation reads the file into an array and then passes the array to doOpenData(). Together with assumptions about data ownership it causes an extra copy that can be avoided by providing a dedicated doOpenFile() implementation. Commit mosra/magnum-plugins@8e21c2f.
- 9.
- ^ a b If the importer can make a few more assumptions about data ownership,
the returned mesh data can be actually a view onto the memory given on
input, getting rid of another copy. There’s still some overhead left from
deinterleaving the index buffer, so it’s not faster than a plain
cat. A custom file format allows the import to be done in 0.002 seconds, with the actual data reading deferred to the point where the GPU needs it — and then feeding the GPU straight from a (memory-mapped) SSD. Neither of those is integrated intomasteryet, see A peek into the future — Magnum’s own memory-mappable mesh format below.
STL (“stereolithography”)

STL — for each triangle a normal, three corner positions and optional color data
The STL format is extremely simple — just a list of triangles, each containing a normal and positions of its corners. It’s commonly used for 3D printing, and thus the internet is also full of interesting huge files for testing. Until recently, Magnum used AssimpImporter to import STLs, and to do another comparison I implemented a StlImporter from scratch. Taking a 104 MB file (source, alternative), here’s the times — AssimpImporter is configured the same as above4 and similar optimizations8 as in StanfordImporter were done here as well:
- 10.
- ^ Because the normals are per-triangle, turning them into per-vertex
increases the data size roughly by a half (instead of 16 floats per
triangle it becomes 24). Disabling this (again with a
perFaceToPerVertexoption) significantly improves import time. Commit mosra/magnum-plugins@e013040.
MeshOptimizer and plugin interfaces for mesh conversion
While the MeshTools library provides a versatile set of APIs for various mesh-related tasks, it’ll never be able to suit the needs of everyone. Now that there’s a flexible-enough mesh representation, it made sense to extend the builtin engine capabilities with external mesh conversion plugins.
The first mesh processing plugin is MeshOptimizerSceneConverter, integrating meshoptimizer by @zeuxcg. Author of this library is also responsible for the KHR_mesh_quantization extension and it’s all-round a great piece of technology. Unleashing the plugin in its default config on a mesh will perform the non-destructive operations — vertex cache optimization, overdraw optimization and vertex fetch optimization. All those operations can be done in-place on an indexed triangle mesh using convertInPlace():
Containers::Pointer<Trade::AbstractSceneConverter> meshoptimizer = manager.loadAndInstantiate("MeshOptimizerSceneConverter"); meshoptimizer->convertInPlace(mesh);
Okay, now what? This may look like one of those impossible Press to render fast magic buttons, and since the operation took about a second at most and didn’t make the output smaller in any way, it can’t really do wonders, right? Well, let’s measure, now with a 179 MB scan3 containing 7.5 million triangles with positions and vertex colors, how long it takes to render before and after meshoptimizer looked at it:
To simulate a real-world scenario, the render was deliberately done in a default camera location, with a large part of the model being out of the view. Both measurements are done using the (also recently added) DebugTools::GLFrameProfiler, and while GPU time measures the time GPU spent rendering one frame, vertex fetch ratio shows how many times a vertex shader was executed compared to how many vertices were submitted in total. For a non-indexed triangle mesh the value would be exactly 1.0, with indexed meshes the lower the value is the better is vertex reuse from the post-transform vertex cache11. The results are vastly different for different GPUs, and while meshoptimizer helped reduce the amount of vertex shader invocations for both equally, it helped mainly the Intel GPU. One conclusion could be that the Intel GPU is bottlenecked in ALU processing, while the AMD card not so much and thus reducing vertex shader invocations doesn’t matter that much. That said, the shader used here was a simple Shaders::Phong, and the impact could be likely much bigger for the AMD card with complex PBR shaders.
- 11.
- ^ Unfortunately the ARB_pipeline_statistics_query extension doesn’t provide a way to query the count of indices submitted, so it’s not possible to know the overfetch ratio — how many times the vertex shader had to be executed for a single vertex. This is only possible if the submitted indices would be counted on the engine side.
Apart from the above, the MeshOptimizerSceneConverter plugin can also optionally decimate meshes. As that is a destructive operation, it’s not enabled by default, but you can enable and configure it using plugin-specific options:
meshoptimizer->configuration().setValue("simplify", true); meshoptimizer->configuration().setValue("simplifyTargetIndexCountThreshold", 0.5f); Containers::Optional<Trade::MeshData> simplified = meshoptimizer->convert(mesh);
Together with the mesh processing plugins, and similarly to image converters, there’s a new magnum-sceneconverter command-line tool that makes it possible to use these plugins together with various mesh tools directly on scene files. Its use is quite limited at this point as the only supported output format is PLY (via StanfordSceneConverter) but the tool will gradually become more powerful, with more output formats. As an example, here it first prints an info about the mesh, then takes just the first attribute, discarding per-face normals, removes duplicate vertices, processes the data with meshoptimizer on default settings and saves the output to a PLY:
magnum-sceneconverter dragon.stl --info
Mesh 0: Level 0: MeshPrimitive::Triangles, 6509526 vertices (152567.0 kB) Offset 0: Trade::MeshAttribute::Position @ VertexFormat::Vector3, stride 24 Offset 12: Trade::MeshAttribute::Normal @ VertexFormat::Vector3, stride 24
magnum-sceneconverter dragon.stl dragon.ply \ --only-attributes "0" \ --remove-duplicates \ --converter MeshOptimizerSceneConverter -v
Trade::AnySceneImporter::openFile(): using StlImporter Duplicate removal: 6509526 -> 1084923 vertices Trade::MeshOptimizerSceneConverter::convert(): processing stats: vertex cache: 5096497 -> 1502463 transformed vertices 1 -> 1 executed warps ACMR 2.34879 -> 0.69243 ATVR 4.69757 -> 1.38486 vertex fetch: 228326592 -> 24462720 bytes fetched overfetch 17.5378 -> 1.87899 overdraw: 107733 -> 102292 shaded pixels 101514 -> 101514 covered pixels overdraw 1.06126 -> 1.00766 Trade::AnySceneConverter::convertToFile(): using StanfordSceneConverter
The -v option translates to Trade::SceneConverterFlag::Verbose,
which is another new feature that enables plugins to print extended info about
import or processing. In case of
MeshOptimizerSceneConverter it
analyzes the mesh before and after, calculating average cache miss ratio,
overdraw and other useful metrics for mesh rendering efficiency.
Going further — custom attributes, face and edge properties, meshlets
To have the mesh data representation truly future-proofed, it isn’t enough to limit its support to just the “classical” indexed meshes with attributes of predefined semantics and a (broad, but hardcoded) set of vertex formats.
Regarding vertex formats, similarly as is done since 2018.04 for pixel formats, a mesh can contain any attribute in an implementation-specific format. One example could be normals packed into for example VK_FORMAT_A2R10G10B10_SNORM_PACK32 (which currently doesn’t have a generic equivalent in VertexFormat) — code that consumes the Trade::MeshData instance can then unwrap the implementation-specific vertex format and pass it directly to the corresponding GPU API. Note that because the library has no way to know anything about sizes of implementation-specific formats, such instances have only limited use in MeshTools algorithms.
Trade::MeshAttributeData normals{Trade::MeshAttribute::Normal, vertexFormatWrap(VK_FORMAT_A2R10G10B10_UNORM_PACK32), data};
Meshes don’t stop with just points, lines or triangles anymore. Together with Trade::AbstractImporter::mesh() allowing a second parameter specifying mesh level (similarly to image mip levels), this opens new possibilities — STL and PLY importers already use it to retain per-face properties, as shown below on one of the pbrt-v3 sample scenes:
# Disabling the perFaceToPerVertex option to keep face properties as-is magnum-sceneconverter dragon_remeshed.ply --info \ --importer StanfordImporter -i perFaceToPerVertex=false
Mesh 0 (referenced by 0 objects): Level 0: MeshPrimitive::Triangles, 924422 vertices (10833.1 kB) 5545806 indices @ MeshIndexType::UnsignedInt (21663.3 kB) Offset 0: Trade::MeshAttribute::Position @ VertexFormat::Vector3, stride 12 Level 1: MeshPrimitive::Faces, 1848602 vertices (21663.3 kB) Offset 0: Trade::MeshAttribute::Normal @ VertexFormat::Vector3, stride 12
Among other possibilities is using MeshPrimitive::Edges to store meshes in half-edge representation (the endlessly-flexible PLY format even has support for per-edge data, although the importer doesn’t support that yet), MeshPrimitive::Instances to store instance data (for example to implement the proposed glTF EXT_mesh_gpu_instancing extension) or simply provide additional LOD levels (glTF has a MSFT_lod extension for this).
~ ~ ~
struct meshopt_Meshlet { unsigned int vertices[64]; unsigned char indices[126][3]; unsigned char triangle_count; unsigned char vertex_count; };
Source: meshoptimizer.h
Ultimately, we’re not limited to predefined primitive and attribute types
either. The most prominent example of using this newly gained flexibility is
mesh shaders and meshlets.
Meshlets are a technique that is becoming more and more important for dealing
with heavy geometry, and meshoptimizer has an
experimental support for those12. For given input it generates a sequence
of statically-defined meshopt_Meshlet structures that are then meant to
be fed straight to the GPU.
Describing such data in a Trade::MeshData instance is a matter of defining a set of custom attribute names and listing their offsets, types and array sizes, as shown below. While a bit verbose at first look, an advantage of being able to specify the layout dynamically is that the same attributes can work for representations from other tools as well, such as meshlete.
/* Pick any numbers that don't conflict with your other custom attributes */ constexpr auto Meshlet = meshPrimitiveWrap(0xabcd); constexpr auto MeshletVertices = Trade::meshAttributeCustom(1); constexpr auto MeshletIndices = Trade::meshAttributeCustom(2); constexpr auto MeshletTriangleCount = Trade::meshAttributeCustom(3); constexpr auto MeshletVertexCount = Trade::meshAttributeCustom(4); Trade::MeshData meshlets{Meshlet, std::move(meshletData), { Trade::MeshAttributeData{MeshletVertices, VertexFormat::UnsignedInt, offsetof(meshopt_Meshlet, vertices), 0, sizeof(meshopt_Meshlet), 64}, Trade::MeshAttributeData{MeshletIndices, VertexFormat::Vector3ub, offsetof(meshopt_Meshlet, indices), 0, sizeof(meshopt_Meshlet), 126}, Trade::MeshAttributeData{MeshletTriangleCount, VertexFormat::UnsignedByte, offsetof(meshopt_Meshlet, triangle_count), 0, sizeof(meshopt_Meshlet)}, Trade::MeshAttributeData{MeshletVertexCount, VertexFormat::UnsignedByte, offsetof(meshopt_Meshlet, vertex_count), 0, sizeof(meshopt_Meshlet)}, }, meshletCount};
One important thing to note is the array attributes — those are accessed with a special syntax, and give you a 2D view instead of a 1D one:
Containers::StridedArrayView1D<const UnsignedByte> triangleCount = meshlets.attribute<UnsignedByte>(MeshletTriangleCount); Containers::StridedArrayView2D<const Vector3ub> indices = meshlets.attribute<Vector3ub[]>(MeshletIndices); for(Vector3ub triangle: indices[i].prefix(triangleCount[i])) { // do something with each triangle of meshlet i … }
- 12.
- ^ Not mentioned in the project README, you need to look directly in the source. At the time of writing, meshlet generation isn’t integrated into the MeshOptimizerSceneConverter plugin yet — but it’ll be, once I get a hardware to test the whole mesh shader pipeline on. If you want to play with them, there’s a recent introduction on Geeks3D covering both OpenGL and Vulkan.
Visualize the happiness of your data
When working with mesh data of varying quality and complexity, it’s often needed to know not only how the mesh renders, but also why it renders that way. The Shaders::MeshVisualizer got extended to have both a 2D and 3D variant and it can now visualize not just wireframe, but also tangent space13 — useful when you need to know why your lighting or a normal map is off —, object ID for semantic annotations or for example when you have multiple meshes batched together14, and finally two simple but very important properties — primitive and vertex ID.
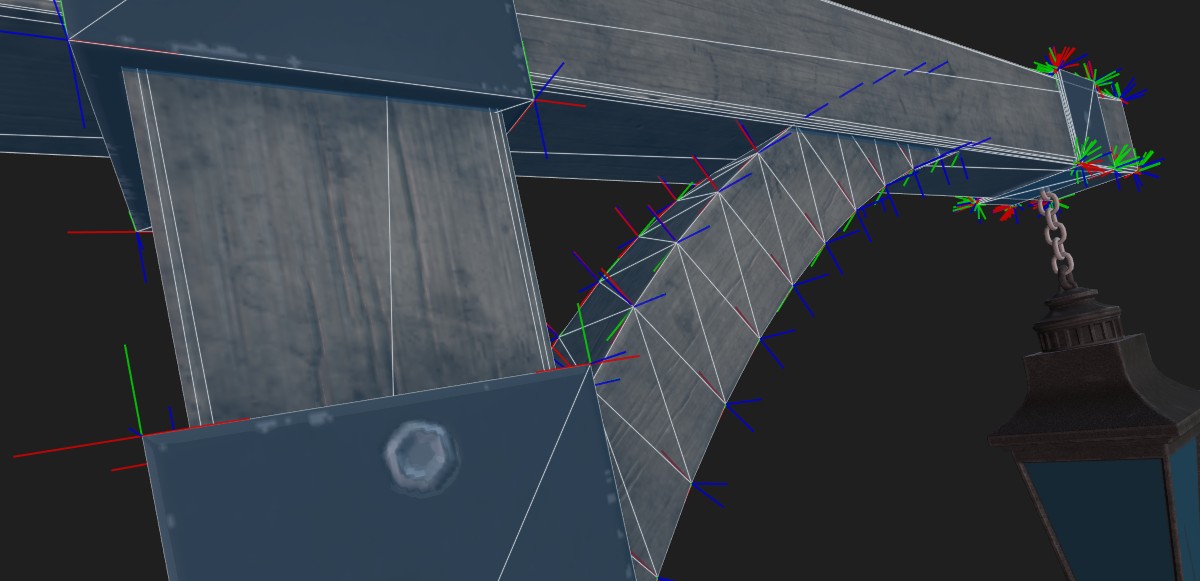



On the truck wheel15 above you can see a very “rainbowy” primitive ID visualization, which hints that the vertices are not rendered in an order that would make good use of the vertex cache (and which can MeshOptimizerSceneConverter help with). Vertex ID, on the other hand, can point to discontinuities in the mesh — even though the blanket3 above would look like a smooth continuous mesh to a naked eye, the visualization uncovers that almost none of the triangles share a common vertex, which will likely cause issues for example when decimating the mesh or using it for collision detection.
Supplementary to the mesh visualizer is a gallery of color maps for balanced and easily recognizable visualizations. The above images were created using the Turbo color map and DebugTools::ColorMap provides four more that you can choose from.
Lastly, and as already mentioned above, you’re encouraged to use DebugTools::FrameProfiler to measure various aspects of mesh renderer, both on the CPU and GPU side and with builtin support for custom measurements and delayed queries to avoid stalls. Hooking up this profiler doesn’t mean you suddenly need to deal with UI and text rendering — it can simply print its output to a terminal as well, refreshing itself every once in a while:
Last 50 frames: Frame time: 16.65 ms CPU duration: 14.72 ms GPU duration: 10.89 ms Vertex fetch ratio: 0.24 Primitives clipped: 59.67 %
- 3.
- ^ a b c The Matterport3D indoor environment scans were used as a source for various timings, benchmarks and visualizations
- 13.
- ^ Model source: Lantern from the glTF Sample Models repository
- 14.
- ^ Screenshot from a semantics-annotated scan from the Replica dataset
- 15.
- ^ Model source: Cesium Milk Truck from the glTF Sample Models repository
Referencing external data, avoiding copies
One of the ubiquitous annoying problems when dealing with STL containers is memory management inflexibility — you can’t really16 convince a std::vector to reference external memory or, conversely, release its storage and reuse it elsewhere. The new Trade::MeshData (and Trade::AnimationData + Trade::ImageData as well, for that matter) learned from past mistakes and can act as a non-owning reference to external index and vertex buffers as well as attribute descriptions.
For example it’s possible store index and vertex buffer for a particular model in constant memory and make Trade::MeshData just reference it, without any allocations or copies. In Magnum itself this is used by certain primitives such as Primitives::cubeSolid() — since a cube is practically always the same, it doesn’t make sense to build a copy of it in dynamic memory every time.
Another thing the API was explicitly designed for is sharing a single large buffer among multiple meshes — imagine a glTF file containing several different meshes, but all sharing a single buffer that you upload just once:
/* Shared for all meshes */ Containers::ArrayView<const char> indexData; Containers::ArrayView<const char> vertexData; GL::Buffer indices{indexData}; GL::Buffer vertices{indexData}; GL::Mesh chair = MeshTools::compile(chairData, indices, vertices); GL::Mesh tree = MeshTools::compile(treeData, indices, vertices); // …
Lastly, nothing prevents Trade::MeshData from working in an “inverse” way — first use it to upload a GPU buffer, and then use the same attribute layout to conveniently perform modifications when the buffer gets mapped back to CPU memory later.
- 16.
- ^ Standard Library design advocates would mention that you can use a custom allocator to achieve that. While that’s technically true, it’s not a practical solution, considering the sheer amount of code you need to write for an allocator (when all you really need is a custom deleter). Also, have fun convincing 3rd party vendors that you need all their APIs to accept std::vectors with custom allocators.
A peek into the future — Magnum’s own memory-mappable mesh format
Expanding further on the above-mentioned ability to reference external data, it’s now possible to have Trade::MeshData pointing directly to contents of a memory-mapped file in a compatible format, achieving a truly zero-copy asset loading. This is, to some extent, possible with all three — STL, PLY and glTF — file formats mentioned above. A work-in-progress PR enabling this is mosra/magnum#240, what I still need to figure out is interaction between memory ownership and custom file loading callbacks; plus in case of glTF it requires writing a new importer plugin based on cgltf as TinyGltfImporter (and tiny_gltf in particular) can’t really be convinced to work with external buffers due to its heavy reliance on std::vectors.
At some point I realized that even with all flexibility that glTF provides, it’s still not ideal due to its reliance on JSON, which can have a large impact on download sizes of WebAssembly builds.
What would a minimalist file format tailored for Magnum look like, if we
removed everything that can be removed? To avoid complex parsing and data
logistics, the file format should be as close to the binary representation of
Trade::MeshData as possible, allowing the actual payload to be used
directly without any processing, and the deserialization process being just a
handful of sanity and range checks. With that, it’s then possible to have
import times smaller than what would a cp file.blob > /dev/null take
(as shown above), because we don’t actually need to read
through all data at first — only when given portion of the file is meant to
be uploaded to the GPU or processed in some other way:
/* Takes basically no time */ Containers::Array<char, Utility::Directory::MapDeleter> blob = Utility::Directory::mapRead("file.blob"); /* Does a bunch of checks and returns views onto `blob` */ Containers::Optional<Trade::MeshData> chair = Trade::MeshData::deserialize(blob);
Another aspect of the format is easy composability and extensibility — inspired by RIFF and design of the PNG file header, it’s composed of sized chunks that can be arbitrarily composed together, allowing the consumer to pick just a subset and ignore the rest. Packing a bunch of meshes of diverse formats together into a single file could then look like this:
magnum-sceneconverter file.blend --mesh "chair" chair.blob magnum-sceneconverter scene.glb --mesh "tree" tree.blob … cat chair.blob tree.blob car.blob > blobs.blob # because why not
Initial working implementation of all the above together with detailed format specification is in mosra/magnum#427, and the end goal is to be able to describe not just meshes but whole scenes. It’s currently living in a branch because the last thing a file format needs is compatibility issues — it still needs a few more iterations before its design settles down. This then goes hand-in-hand with extending Trade::AbstractSceneConverter to support more than just meshes alone, thus also making it possible to output glTF files with magnum-sceneconverter, among other things.
* * *
And that’s it for now. Thanks for reading and stay tuned for further advances in optimizing the asset pipeline.